 ※画像は生成AIによるイメージです
※画像は生成AIによるイメージです Felo Agentで自社マニュアルをAIエージェントに学習させる:PDF・ドキュメント活用術
企業が競争優位性を確立するためには、独自の知識やノウハウが不可欠です。しかし、これらの貴重な情報が紙媒体のマニュアルや散在するデジタルファイルに埋もれ、必要な時に活用しきれていないケースも少なくありません。AIエージェントは、このような課題を解決する強力なツールとなり得ます。汎用的なAIが提供する一般的な知識だけでなく、自社の特定のデータに基づいて学習することで、より専門的で実用的な情報を提供するAIエージェントを構築できます。
本記事は、全5回の連載「Felo Agent 使い方 初心者 自作」の第3回として、Felo Agentを活用して自社のPDFファイルやマニュアルなどのドキュメントをAIエージェントに学習させる具体的な手順と、そのビジネスにおける価値について深く掘り下げて解説します。
なぜ自社データをAIエージェントに学習させるのか? - 汎用AIの限界とビジネス価値
AI技術の進化は目覚ましく、ChatGPTのような大規模言語モデル(LLM)は、幅広い質問に対して自然な文章で回答する能力を持っています。しかし、これらの汎用AIが持つ知識は、主にインターネット上の公開情報や学習データセットに含まれる一般的な情報に限られます。企業が持つ独自の製品情報、社内規定、顧客対応履歴、特定の業務プロセスに関するマニュアルといった機密性の高い情報やニッチな専門知識は、汎用AIの学習範囲外です。
ここで、自社データをAIエージェントに学習させることの重要性が浮上します。
1. 専門性と精度の向上
自社の製品マニュアルや技術資料を学習させることで、AIエージェントは製品の機能、トラブルシューティング、仕様に関する質問に対して、公式かつ正確な情報を基に回答できるようになります。これにより、顧客サポートの品質向上や、社内問い合わせ対応の効率化が期待できます。特定の業界用語や社内ルールに即した回答も可能となり、一般的なAIでは得られない専門的な洞察を提供します。
2. 業務効率の大幅な改善
例えば、新入社員が膨大な社内マニュアルの中から必要な情報を探し出す手間は、AIエージェントが代替できます。特定のキーワードや自然言語での質問に対し、関連するマニュアル箇所を瞬時に提示することで、情報探索にかかる時間を劇的に短縮し、本来の業務に集中できる環境を構築します。営業部門では、顧客からの製品に関する質問に対し、AIエージェントが学習した最新の製品情報を基に即座に回答することで、商談のスピードアップと成約率向上に貢献します。
3. 顧客体験の向上
顧客が製品やサービスについて問い合わせる際、AIエージェントが自社データに基づいた正確かつ迅速な回答を提供できれば、顧客満足度は飛躍的に向上します。FAQではカバーしきれない複雑な質問にも対応できるようになり、顧客は24時間365日、必要な情報を手に入れられるようになります。これは、企業ブランドの信頼性向上にも直結します。
4. 意思決定の迅速化
蓄積された過去のプロジェクトデータ、市場調査レポート、競合分析資料などをAIエージェントに学習させることで、経営層や管理職はデータに基づいた意思決定を迅速に行うことができます。特定の市場トレンドや過去の成功・失敗事例を瞬時に引き出し、戦略立案の精度を高めることが可能になります。
自社データ学習は、AIエージェントを単なる「チャットボット」から、企業の「知識のハブ」へと進化させるための重要なステップです。Felo Agentのようなノーコードツールを活用すれば、専門的なプログラミング知識がなくても、これらの恩恵を享受できます。
Felo Agentでのデータ取り込み実践ガイド - PDF・マニュアルを知識源にする手順
Felo Agentでは、自社のドキュメントを「ナレッジベース」としてAIエージェントに学習させることができます。この機能により、アップロードされたPDFファイルやマニュアルの内容をAIが理解し、その知識に基づいて質問に回答できるようになります。ここでは、具体的なデータ取り込み手順と、つまずきやすいポイントについて解説します。
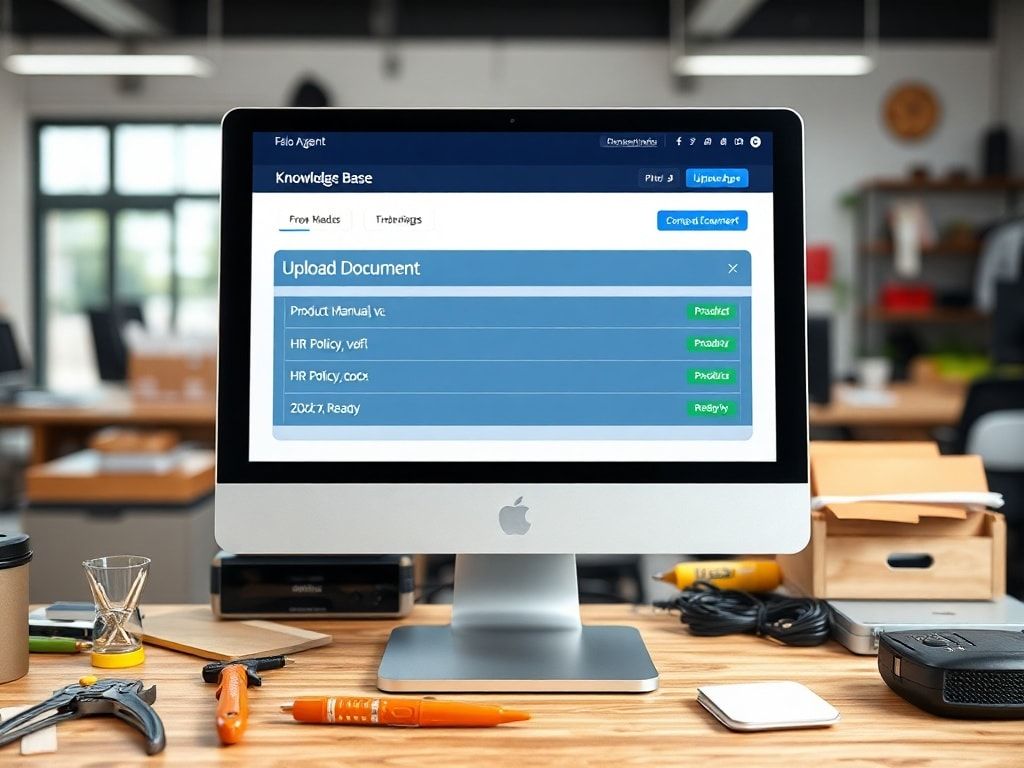
1. ナレッジベースの作成とデータアップロード
Felo Agentのダッシュボードにログイン後、「ナレッジベース」または「データソース」といった項目を探します。通常は左側のメニューバーや中央のワークスペースに配置されています。
- 新規ナレッジベースの作成: まず、新しいナレッジベースを作成します。これにより、特定の目的やエージェントに紐づくデータ群を管理できます。例えば、「製品マニュアル」用、「社内規定」用といった形で分類すると、後々の管理が容易になります。
- ファイルの種類を選択: Felo Agentがサポートするファイル形式は、PDF、DOCX(Word文書)、TXT(テキストファイル)などが一般的です。スキャンされた画像形式のPDF(画像PDF)の場合、テキストが埋め込まれていないため、AIが内容を読み取れないことがあります。この場合は、OCR(光学文字認識)処理が可能なツールでテキスト情報を抽出した上でアップロードするか、Felo Agentが内部でOCR処理をサポートしているかを確認する必要があります。
- ファイルのアップロード: 「ファイルを追加」や「アップロード」ボタンをクリックし、学習させたいPDFファイルやマニュアルを選択してアップロードします。複数のファイルを一度に選択してアップロードできる場合もあれば、一つずつアップロードする必要がある場合もあります。ファイルサイズに上限が設けられていることが多いので、大規模なマニュアルをアップロードする際は、分割を検討するか、Felo Agentの料金プランによる制限を確認してください。
 ※画像は生成AIによるイメージです
※画像は生成AIによるイメージです
2. データ処理と学習の確認
ファイルをアップロードすると、Felo Agentは自動的にその内容を解析し、AIが理解できる形式に変換する処理を開始します。この処理には、ファイルのサイズや内容の複雑さに応じて時間がかかる場合があります。
- 処理状況の確認: アップロードしたファイルのステータスが「処理中」から「完了」や「準備完了」に変わるのを確認します。エラーが発生した場合は、エラーメッセージを確認し、ファイル形式や内容に問題がないか再確認します。
- 学習内容のプレビュー(もしあれば): 一部のAIエージェント構築ツールでは、学習された内容の一部をプレビューしたり、検索テストを行ったりできる機能が提供されています。これにより、AIがドキュメントの内容を正しく理解しているかを確認できます。
3. AIエージェントへの連携
ナレッジベースが準備できたら、いよいよAIエージェントにその知識を使わせる設定を行います。
- エージェント設定画面へ移動: 構築中のAIエージェントの設定画面を開きます。
- ナレッジベースの紐付け: 通常、「データソース」「知識源」といった項目で、作成したナレッジベースを選択し、エージェントに紐付けます。これにより、エージェントは質問を受けた際に、このナレッジベース内の情報を参照して回答を生成するようになります。
- プロンプトでの指示: エージェントの「役割(Role)」や「タスク(Task)」を定義するプロンプトにおいて、「提供されたナレッジベース内の情報を参照し、回答を生成してください」といった明確な指示を含めることが重要です。これにより、AIは汎用的な知識だけでなく、自社データを優先的に活用するようになります。例えば、「あなたは当社の製品サポート担当者です。顧客からの質問には、提供された最新の製品マニュアル(ナレッジベース)を参照し、正確かつ簡潔に回答してください。」といった形で指示します。
つまずきやすいポイントと解決策
- 画像PDFの取り扱い: スキャンしたPDFはテキスト情報が含まれないため、AIが読み取れません。事前にOCRツールでテキスト化するか、Felo AgentのOCR機能の有無を確認してください。
- ファイルサイズの制限: 大容量のファイルをアップロードできない場合は、ファイルを分割したり、不要なページを削除したりしてサイズを最適化します。
- フォーマットの複雑さ: 表やグラフが多い、レイアウトが複雑なドキュメントは、AIが正確に情報を抽出できない場合があります。可能な限りシンプルなテキスト形式に変換したり、重要な情報をテキストとして別途抽出したりする工夫が必要です。
- 多言語対応: 複数言語のマニュアルを学習させる場合は、Felo Agentが多言語に対応しているか確認が必要です。
- 機密情報の管理: 機密性の高い情報をアップロードする際は、セキュリティ対策やアクセス権限の設定を十分に確認し、情報漏洩のリスクを最小限に抑えるようにしてください。
学習済みデータを最大限に活用するコツと注意点 - エージェントの精度を高める運用
AIエージェントの精度は、学習させるデータの質と量に大きく依存します。ナレッジベースの構築は一度きりの作業ではなく、継続的な運用と改善が不可欠です。
1. データの品質管理と鮮度維持
- データの正確性: 学習させるデータは、常に最新かつ正確な情報である必要があります。古い情報や誤った情報が含まれていると、AIエージェントが不正確な回答を生成し、ユーザーの信頼を損ねる可能性があります。定期的なデータレビューと更新プロセスを確立してください。
- データの網羅性: エージェントに回答させたい質問の範囲をカバーする十分な情報がナレッジベースに含まれているかを確認します。特定の質問に対して情報が不足している場合は、関連するドキュメントを追加学習させる必要があります。
- データの整理と重複排除: 複数のドキュメントに同じ情報が重複して記載されていると、AIが混乱したり、無駄な処理が発生したりする原因になります。可能な限り重複を避け、情報を一元的に管理するよう努めてください。
2. プロンプトと学習データの連携強化
AIエージェントは、プロンプトで与えられた指示と学習データに基づいて回答を生成します。この2つの要素を効果的に連携させることが、精度の高いエージェントを構築する鍵です。
- 明確な指示: プロンプトには、「ナレッジベースを参照して回答を生成すること」「ナレッジベースに情報がない場合は、その旨を伝えること」など、AIエージェントの振る舞いを明確に指示します。
- 関連性の高い情報の強調: 特定の質問に対して、ナレッジベース内のどの情報が最も関連性が高いかをAIに示唆するようなプロンプトの記述も有効です。例えば、「以下の質問に対し、特に『製品Aのトラブルシューティングガイド』を参照して回答してください。」といった具体的な指示です。
3. テストと改善のサイクル
AIエージェントは一度構築したら終わりではありません。実際の運用を通じて、その性能を継続的に評価し、改善していく必要があります。
- 広範なテスト: エージェントが提供する情報が、期待される品質と正確性を満たしているかを確認するために、多様な質問やシナリオで徹底的にテストを行います。特に、ナレッジベース内の情報に依存する質問を重点的にテストしてください。
- ユーザーフィードバックの活用: 実際のユーザーからのフィードバックは、エージェントの改善に不可欠な情報源です。回答の正確性、分かりやすさ、対応範囲などに関するフィードバックを収集し、ナレッジベースの更新やプロンプトの調整に活かします。
- 回答の検証と修正: エージェントが不適切な回答を生成した場合、その原因を特定し、学習データの修正、プロンプトの最適化、またはエージェントのモデル設定の見直しを行います。このイテレーション(反復)を通じて、エージェントの精度は徐々に向上していきます。
 ※画像は生成AIによるイメージです
※画像は生成AIによるイメージです
4. セキュリティとコンプライアンス
自社データをAIエージェントに学習させる際には、情報セキュリティとコンプライアンスに関する配慮が不可欠です。
- アクセス管理: ナレッジベースへのアクセス権限を適切に設定し、許可されたユーザーのみがデータにアクセス・変更できるようにします。
- データ暗号化: アップロードされたデータがFelo Agentのプラットフォーム上で適切に暗号化されているかを確認し、データ保護の体制を理解しておくことが重要です。
- プライバシーポリシーの確認: Felo Agentの利用規約やプライバシーポリシーを確認し、自社データの取り扱いに関する規定を理解しておく必要があります。特に、個人情報や機密情報を含むデータを扱う場合は、その取り扱いが法規制や社内ポリシーに準拠しているかを確認してください。
Felo Agentを活用した自社データ学習は、企業が持つ膨大な知識を「生きた情報資産」へと変え、ビジネスのあらゆる側面で価値を創出する可能性を秘めています。ノーコードでAIエージェントを構築できるFelo Agentは、非エンジニアでもこの強力なツールを使いこなし、業務効率化とビジネス成長を加速させるための最適な選択肢となるでしょう。 次回は、AIエージェントの「思考プロセス」を深掘りし、より複雑なタスクを実行させるための「ツール連携」について解説します。
関連アイテム
この記事に関連する製品カテゴリを Amazon で探す → (アフィリエイトリンクを含みます)